Three-Layer Control: How DesireCore Makes AI Agents Truly Trustworthy
Introduction: The Trust Gap in the Age of AI
We live in a time of profound contradiction.
On one hand, AI capabilities have far surpassed what most people imagined possible. Large language models can draft legal contracts, analyze financial statements, write production-grade code, and plan marketing campaigns — tasks that would have been considered science fiction just two years ago. On the other hand, AI adoption rates in real-world production environments remain far below expectations. McKinsey’s research shows that while over 70% of enterprises have “experimented” with AI, fewer than 15% have actually deployed it into core business processes.
This massive gap is not a matter of technical capability. It is a matter of trust.
Let us reframe the problem. Imagine you have just hired an extraordinarily talented new employee — top-tier education, impressive resume, stellar interview performance. But once he settles into his desk, you notice a few things: you cannot see what he is doing (his office door is always closed), you cannot limit his access (he has the highest-level credentials to every company system), and you cannot undo his actions (every decision he makes is irreversible).
No matter how capable this employee might be, would you trust him with your core business operations?
The answer is obviously no. And this is exactly the predicament that most people face when it comes to AI agents today.
The fundamental question is not “Can AI do this job well?” but rather “Do I dare let AI do this job?” Capability is a necessary condition for trust, but it is far from sufficient. Trust also requires transparency, control, and fault tolerance.
From its inception, DesireCore has treated this trust problem as the central design challenge. Rather than offering hollow reassurances like “our AI is safe,” we have built a systematic three-layer control architecture — Visible, Controllable, Reversible — that ensures users maintain complete authority over their AI agents at the mechanism level.
This article provides a comprehensive exploration of the design philosophy, implementation details, and synergistic dynamics of these three layers, helping you understand why trust is not something you promise — it is something you design.
Part One: Visibility — Every Step of AI in Broad Daylight
1.1 Why Visibility Is the Foundation of Trust
There is a classic management principle: “You cannot manage what you cannot see.” This principle applies with equal — if not greater — force in the context of AI agents.
Traditional AI chat tools deliver a “black box” experience. You enter a question, the AI produces an answer. You have no idea how it arrived at that answer, what information it consulted during its “thinking” process, what judgments it made, or what possibilities it discarded. This black-box approach may be acceptable for simple Q&A scenarios, but when AI begins executing complex multi-step tasks, it becomes entirely unacceptable.
Consider this scenario: you ask an AI agent to process a batch of customer data — clean the format, identify outliers, and generate an analysis report. If all you can see is the final report, with no visibility into what the AI did to the raw data along the way, how can you assess whether the report is trustworthy? Did it mistakenly delete certain records? Were its outlier detection criteria reasonable? Did it accidentally modify the production database?
You have no way of knowing. And when you have no way of knowing, you cannot rely on the result.
This is why visibility is the first foundational layer of trust. DesireCore’s visibility design goes far beyond displaying a “processing…” progress bar — it exposes every action, every decision, and every operation to the user’s full view.
1.2 Four Dimensions of Visibility
DesireCore’s visibility unfolds across four dimensions, each addressing a core question:
Real-Time Status Visibility — “What is the AI doing right now?”
In DesireCore, every AI agent’s current status is observable in real time. After you delegate a task to an agent, you can open its work panel at any moment to see which stage it is at: collecting information, analyzing data, calling a tool, or waiting for an external service to respond. This real-time status transparency is like being able to walk over to that new employee’s desk at any time and see what they are working on.
The value of this visibility is twofold. First, it eliminates the anxiety of waiting — you no longer need to stare at a blank screen wondering whether the AI has stalled. Second, it allows you to catch problems early — if the AI appears to be heading down a wrong path, you can intervene immediately rather than discovering at the end that the entire task has gone off the rails.
Decision Process Visibility — “Why did the AI make this decision?”
Knowing “what” the AI is doing is not enough. Users often want to know “why” it is doing it. DesireCore provides full visibility into the decision-making process: at every key decision point, the AI displays its reasoning — which rules it consulted, which factors it weighed, and how it chose among multiple options.
For example, when the AI flags a particular clause in a contract as risky, it will not just display a red warning. It will explain: “Based on your risk assessment rules, the ‘force majeure’ definition in this clause is overly narrow compared to industry standards, lacking coverage for ‘government actions’ and ‘supply chain disruptions,’ which could be disadvantageous under certain circumstances.” This decision transparency lets users evaluate the quality of the AI’s judgment rather than being forced to trust it unconditionally.
Change Content Visibility — “What did the AI change?”
When the AI needs to modify files or data, DesireCore presents changes in diff format — red for deletions, green for additions. This presentation is familiar to software developers (it is essentially the diff view from code review), but DesireCore extends this intuitive change display to all types of content, including documents, configuration files, and data tables.
The core value of diff display is this: it lets users know precisely what the AI changed without having to compare the complete pre- and post-modification files word by word. This dramatically reduces review costs and makes users more willing to delegate “modification” tasks to AI — because reviewing changes takes seconds, not minutes.
Tool Call Visibility — “What tools did the AI use?”
One of the key differences between AI agents and traditional AI chatbots is that agents can invoke external tools — search engines, databases, API endpoints, file systems, and more. These tool calls are the aspect of AI behavior that most demands attention because they involve interactions with the real world.
DesireCore fully displays the details of every tool call: which tool was invoked, what parameters were passed, and what results were returned. Users can see exactly how the AI uses these tools and judge whether its operations are reasonable. For instance, if the AI queries a customer database with overly broad search criteria, the user can spot this immediately rather than waiting until the AI has retrieved a mass of irrelevant data.
1.3 The Visibility Analogy: An Employee Working with the Door Open
Returning to our opening metaphor: visibility is like the employee proactively leaving their office door open — you can see what they are doing at any time, and they do not mind. This is not because you distrust them; it is because transparency is the foundation of effective collaboration. In fact, the best employees are often the ones who most proactively share their work progress, because they are confident in the quality of their work and understand the importance of transparency for team trust.
DesireCore’s AI agents operate on the same principle. Full visibility is not “surveillance” of AI — it is a proactive stance toward building trust.
Part Two: Controllability — A Granular Permission Management System
2.1 From “All or Nothing” to “Precise Tiering”
If visibility answers the question “What can I see?” then controllability answers “What can I decide?”

In most AI products, permission control either does not exist or is extremely coarse-grained — you either give the AI complete freedom or you do not use it at all. This is like either handing an employee a master key card that opens every door in the company or not letting them through the front entrance. In reality, no well-run organization operates at either extreme.
DesireCore introduces a granular permission tiering system that lets users set appropriate behavioral boundaries for AI based on each operation’s risk level and their own degree of trust.
2.2 Three Permission Levels
DesireCore’s permission system is built on three levels:
Allow (Auto-Approve)
Operations marked as “allow” can be executed autonomously by the AI without requesting user approval. This is appropriate for extremely low-risk operations that the user fully trusts the AI to handle — reading public documents, querying public databases, formatting text output, and so on. Setting these low-risk operations to auto-approve lets the AI execute tasks smoothly without unnecessary interaction interruptions.
Ask (Confirm Each Time)
Operations marked as “ask” require user confirmation before execution. This is appropriate for operations that carry some risk but are not severe enough to prohibit entirely — modifying file contents, sending emails, calling paid APIs, and similar actions. Before executing such an operation, the AI pauses, shows the user what it intends to do, and waits for explicit approval before proceeding.
The design of this “ask” mechanism is crucial. It does not simply display a “confirm/cancel” dialog box. Instead, it provides sufficient context for the user to make an informed judgment: what operation the AI plans to execute, why it wants to execute it, and what the expected impact will be. With this complete information, the user can choose to approve, reject, or modify the AI’s action plan.
Deny (Auto-Reject)
Operations marked as “deny” are completely prohibited. Even if the task workflow requires such an operation, the AI will automatically skip it and look for alternatives, or inform the user that it cannot complete a particular step. This is appropriate for operations that the user believes should absolutely never be performed by AI — deleting production data, modifying access permission settings, executing irreversible financial transactions, and the like.
2.3 Real-Time Interruption
Beyond pre-set permissions, DesireCore provides real-time interruption during execution. Users can pause or terminate the AI’s operations at any point during task execution.
This capability may seem simple, but it is critically important in practice. Task execution environments are dynamic — you might receive new information after the AI has started working and realize that the current task direction needs adjustment, or you might observe in the real-time status panel that the AI is doing something unexpected that needs to be stopped immediately.
DesireCore’s real-time interruption is not merely “stop generating text.” In traditional chat AI, clicking the stop button only interrupts text generation — actions the AI has already performed remain unaffected. But in the agent scenario, the AI’s operations have real consequences — it may have already called external tools, modified files, or sent requests. DesireCore’s interruption mechanism ensures that when the user clicks pause, the currently executing operation is safely halted, previously completed operations are clearly logged, and the system awaits the user’s next instruction.
2.4 The Human Gate Mechanism
In certain scenarios, users may not be able to anticipate which operations are high-risk, because risk often depends on specific context. DesireCore addresses this with the “Human Gate” mechanism: automatic pause points placed at critical nodes in a workflow that require the user to personally review and confirm before execution can continue.
The difference between a Human Gate and an “ask” permission is granularity. The “ask” permission is a general setting applied to a class of operations, while a Human Gate is precise control over a specific step within a specific workflow. For example, you might set “modify files” to allow (because most file modifications are safe), while simultaneously placing a Human Gate on the “final publish” step — no matter how smoothly the AI has executed previous steps, it must stop here and wait for your confirmation.
This design of “embedding approval nodes within workflows” lets users enjoy the efficiency of AI automation without losing control over critical decisions.
2.5 Configurable Rules: Building Your Own Security Policy
DesireCore’s permission system is not a one-size-fits-all preset. It is a highly configurable framework. Users can flexibly define permission rules according to their needs. For example:
- “Allow reading any file, but writing files requires my confirmation”
- “Allow calling search engines, but deny access to internal databases”
- “Allow modifying draft documents, but any changes to official documents require approval”
- “Allow sending internal messages, but external emails must be confirmed by me”
These rules can be combined, layered, and inherited to form a complete security policy. Different agents can have different permission configurations — an assistant handling routine tasks may be given broader permissions, while an analyst handling sensitive data should be subject to stricter constraints.
2.6 The Controllability Analogy: Access Cards of Different Levels
Returning to our analogy: controllability is like issuing different-level access cards to different employees — interns can enter the office area but not the server room, regular employees can enter the server room but not the data center, and only the core team can access the data center. Moreover, even when an employee with data center access performs a critical operation, the security system requires secondary authentication.
This is not distrust — it is sound security management. The more important the asset, the more granular the access control needs to be.
Part Three: Reversibility — From “No Undo” to “Multi-Level Undo”
3.1 Why Reversibility Is So Important
Even with perfect visibility and controllability, mistakes are inevitable. This is not a criticism of AI capability — even the best human employees make errors in complex work environments. The question is not whether mistakes will happen, but whether they can be recovered from quickly and at low cost.
In traditional AI tools, reversibility is virtually nonexistent. If the AI generates unsatisfactory text, your only option is to regenerate. If the AI performs an incorrect operation, you can only fix it manually. Worse, in many scenarios, the AI’s operations are irreversible — emails it sent cannot be recalled, data it deleted cannot be restored, configurations it changed cannot be rolled back.
This “irreversibility” is the final and most critical link in the AI trust dilemma. Think about it: if you know that a decision, once made, can never be undone, how would you approach that decision? You would become extremely cautious, double-checking every detail, preferring to do it yourself rather than delegating. This is exactly the mindset many users adopt toward AI agents — the fear of irreversible consequences makes them prefer not to use AI at all.
DesireCore’s multi-level undo mechanism fundamentally changes this equation.
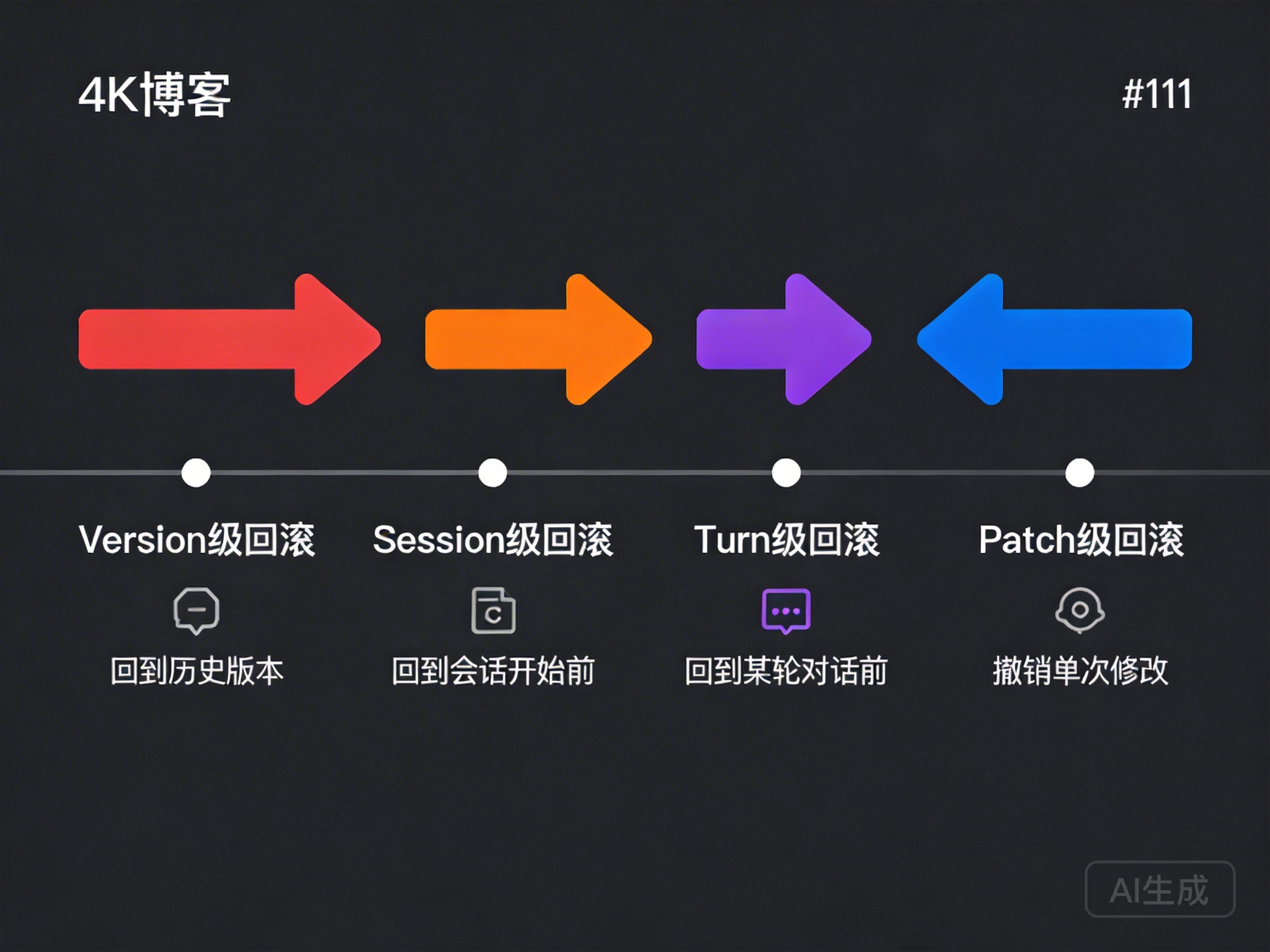
3.2 The Four-Level Rollback System
DesireCore provides four levels of rollback capability, covering every scenario from the finest granularity to the broadest scope:
Patch Level — Step-by-Step Rollback
The finest-grained rollback operates at the level of individual operations. If the AI makes a single modification to a file, you can precisely undo that one modification without affecting other operations from the same task. This is like Ctrl+Z in document editing — undoing one step at a time.
Patch-level rollback is particularly useful when the AI has made a series of modifications but only a few do not meet your expectations. You do not need to discard the entire task’s results — just undo the specific changes you are not satisfied with.
Turn Level — Conversation-Round Rollback
Turn-level rollback corresponds to a complete conversation interaction round. In DesireCore, a single turn typically consists of one user instruction and all operations the AI performs in response. If you discover that the AI went in the wrong direction while responding to a particular instruction, you can roll the system state back to before that instruction was issued and then provide a clearer directive.
Turn-level rollback addresses a common problem: users issue instructions that are not clear enough, causing the AI to misunderstand and perform a batch of useless or even harmful operations. In traditional tools, you would have to manually undo all of them. In DesireCore, a single turn rollback returns you to the correct starting point.
Session Level — Session Rollback
Session-level rollback restores the system state to before the current session began. This is suitable for more serious situations — such as assigning the agent a wrong task or needing to completely readjust the work direction.
The value of session rollback lies in providing a safe “reset point.” No matter what happened during the session, you can return to the pre-session state as if the session never occurred. This gives users tremendous psychological safety — even the boldest experiments have a reliable fallback.
Version Snapshots — Historical Version Recovery
The highest level of rollback is the version snapshot. DesireCore automatically creates snapshots at critical change points for agents, and users can also manually create snapshots. When you need to restore a historical version, simply select the corresponding snapshot.
The version snapshot design draws inspiration from version control systems in software development (like Git), but with substantial simplification and optimization for the AI agent context. Users do not need to understand concepts like commits, branches, and merges — they just select a point in time and click “restore.”
3.3 Technical Guarantees for Rollback
Implementing multi-level rollback is not merely a feature design challenge — it is a fundamental architectural one. DesireCore has invested heavily in the underlying technology:
- Complete operation logging: Every AI operation is recorded in detail, including the operation type, target, pre-operation state, and post-operation state. These logs form the foundation for rollback operations.
- Efficient state snapshot storage: The system creates state snapshots at key points, using incremental storage strategies to avoid excessive space consumption.
- Atomic operation design: Complex operations are decomposed into atomic operations wherever possible, ensuring each step can be independently undone or redone.
- External effect isolation: For operations involving external system interactions (sending requests, writing to databases), DesireCore employs a “stage-then-confirm” two-phase approach that avoids producing real external effects until the user confirms.
3.4 The Reversibility Analogy: A Comprehensive “Undo” for All Actions
If visibility is “working with the door open” and controllability is “issuing access cards,” then reversibility is installing a comprehensive “undo” function for all actions — no matter what the employee does, you can restore things to their original state. With this guarantee, you are no longer afraid to let them try new approaches or handle unfamiliar situations, because you know that the worst case is simply pressing “undo.”
This psychological safety is the key that unlocks AI productivity.
Part Four: Synergy of the Three Layers — Why None Can Be Missing
4.1 The Systemic Nature of the Three-Layer Architecture
The three-layer control system is not three independent features — it is an organically synergistic system. The absence of any single layer creates a fatal vulnerability in the entire trust framework.
Visibility without controllability — forced to watch helplessly
Imagine a scenario: you can clearly see what the AI is doing, but you cannot stop it. You watch it heading step by step toward disaster, powerless to intervene. This is not trust — it is torment. Visibility without controllability actually increases user anxiety — “I can see the problem, but I cannot do anything about it.”
This situation exists in certain AI products. They provide comprehensive logs and status displays, but users have no intervention options beyond “stop.” The result: users become even more hesitant before starting tasks — they can already envision themselves as helpless bystanders.
Controllability without reversibility — the cost of errors is too high
Even with comprehensive permission control and interruption capabilities, if the AI’s completed operations cannot be undone, you will still be extremely cautious. Because in the moment between when you spot a problem and click interrupt, the AI may have already done something irreversible — sent an incorrect email, modified critical data, generated a flawed report and submitted it to a client.
Controllability without reversibility is like a car with brakes but no reverse gear — you can stop before danger, but if you have already gone too far, you cannot go back. In this model, users treat every step as an “irrevocable decision,” and efficiency plummets.
Reversibility without visibility — not knowing when to intervene
If you have perfect rollback capability but cannot see what the AI is doing, how do you know when a rollback is needed? By the time you discover incorrect results, significant time may have passed, numerous operations may be involved, and the cost of rollback becomes very high.
Reversibility without visibility is like having an omnipotent “undo” button that you can only press after things have already gone wrong — you do not know when the problem started, and you do not know which step to roll back to.
4.2 The Positive Feedback Loop of Three-Layer Synergy
When all three layers coexist, they create a positive trust cycle:
- Visibility lets you catch problems early — “That step does not seem right.”
- Controllability lets you act immediately — “Pause, let me take a look.”
- Reversibility eliminates your concerns — “Even if the problem is worse than I thought, I can recover.”
The result of this cycle: users dare to delegate more complex tasks to AI because they know they maintain complete control throughout. As delegated tasks increase, users develop deeper understanding of AI capabilities, and trust continues to accumulate. This creates a virtuous cycle — trust promotes usage, usage deepens trust.
Part Five: The Step Type System — The Elegant Design of Solidified, Flexible, and Human Gates
5.1 Not All Steps Should Be Treated Equally
In real-world workflows, the nature of different steps varies enormously. Some steps are highly deterministic, executed identically every time — such as “move files from folder A to folder B.” Some steps require contextual judgment — such as “analyze this report and suggest improvements.” Others involve major decisions that must be made by humans — such as “decide whether to approve this transaction.”
DesireCore distinguishes these different types of operations through three step categories:
Solidified Steps
Solidified steps are like assembly-line processes — completely determined, completely predictable, completely repeatable. The AI has no room for autonomous judgment when executing solidified steps; it follows predefined rules and procedures exactly.
The value of solidified steps lies in their certainty. Users can predict with 100% accuracy what the AI will do in these steps, so they require no supervision. This dramatically reduces the user’s cognitive burden — you set the rules once, and then you can fully trust the AI’s execution.
Typical solidified step scenarios include: data format conversion, file classification and archiving, scheduled report generation, and template filling. These tasks share a common characteristic: the input-output relationship is deterministic and requires no creativity or judgment.
Flexible Steps
Flexible steps allow the AI to make autonomous judgments and decisions within a defined range. Unlike solidified steps, the output of flexible steps is not predetermined — the AI needs to make optimal choices based on current context, available information, and established objectives.
The design of flexible steps reflects DesireCore’s understanding of the balance between “automation” and “intelligence.” Pure automation (all steps solidified) is efficient but inflexible; pure intelligence (all steps flexible) is flexible but insufficiently controllable. DesireCore lets users choose where AI’s intelligent judgment is needed and where mechanical execution suffices.
Typical flexible step scenarios include: text optimization, customer inquiry classification, anomaly detection, and strategy recommendation. These tasks require AI understanding and judgment, but through visibility mechanisms (displaying the decision process) and controllability mechanisms (setting behavioral boundaries), users can still ensure the AI’s flexible judgments remain within acceptable bounds.
Human Gates
Human Gates are “mandatory approval points” in a workflow. No matter how smoothly the AI has executed previous steps, it must pause at a Human Gate and wait for human review and confirmation.
Human Gates are typically placed based on the following considerations:
- Irreversibility: The step, once executed, is difficult to undo (e.g., publishing an announcement, executing a transaction)
- High impact: The step’s outcome affects important stakeholders (e.g., formal documents sent to clients)
- Compliance requirements: Regulations or company policies mandate that certain decisions be made by humans
- Edge cases: When the AI encounters boundary situations not well covered by its training data or rule base
5.2 Dynamic Adjustment of Step Types
DesireCore’s step types are not fixed. As users develop increasing trust in AI capabilities, they can downgrade certain steps from “Human Gate” to “Flexible Step,” or even further to “Solidified Step.” Conversely, if users find that AI performance on certain steps is insufficiently stable, they can upgrade those steps to require more human oversight.
This dynamic adjustment reflects the gradual process of building trust — trust is not established overnight but accumulates through repeated interaction and verification. DesireCore’s design accommodates this incremental trust-building rather than forcing users into a binary choice between “complete trust” and “complete distrust.”
Part Six: The Receipt System — The Last Mile of Delegation
6.1 From “Task Completed” to “Verifiably Completed”
When you delegate a task to a human colleague, they typically provide a work report upon completion — what they did, how they did it, what problems they encountered, and what the final outcome was. This report is not merely information transfer — it is a handoff of accountability. Through the report, you can verify that the task was indeed completed as expected.
DesireCore’s receipt system systematizes and structures this “work report” mechanism. Whenever an agent completes a delegated task, it automatically generates a detailed receipt report.
6.2 Receipt Content Structure
A complete receipt contains the following sections:
Basic Information
- Task ID and name
- Start time and completion time
- Execution duration
- Delegator and executor
Task Summary
- Original task description
- Summary of actual execution
- Final results and deliverables
- Status: success / partial completion / failure
Technical Details
- List of tools invoked during execution
- Key decision points and their reasoning
- Data sources and reference materials used
- Exceptions encountered and how they were handled
Learning Records
- Patterns or insights newly discovered during execution
- Optimization suggestions for similar future tasks
- Rules and policies triggered during execution
Security Mechanism Records
- Operations blocked by the permission system
- Steps that triggered Human Gate approval
- Risk assessment results
- Data access scope
6.3 Three Core Properties of Receipts
DesireCore’s receipt system is designed around three core principles:
Immutable
Once generated, a receipt cannot be modified. This ensures the receipt’s credibility as “audit evidence” — you can be confident that the receipt’s contents reflect the actual execution, not something that was altered or embellished after the fact. Immutability is essential for compliance audits, accountability tracing, and dispute resolution.
Comprehensive
Receipts cover all critical information about task execution, omitting no important details. This means a reviewer can fully understand how a task was executed from the receipt alone, without needing to consult other logs or records.
Trustworthy
Information in the receipt comes from objective system records, not the AI’s subjective “recollection.” AI may produce hallucinations (fabricating nonexistent information) in text generation, but the data in the receipt system comes directly from system logs and operation records, bypassing the AI’s text generation layer and ensuring information authenticity.
6.4 The Value of Receipts
The receipt system solves the “last mile” trust problem in AI delegation. It lets users know not only that a task “was completed” but also “how it was completed” and “how well it was completed.” This detailed result delivery enables users to:
- Verify whether AI execution met expectations
- Discover potential issues in AI execution processes
- Build understanding of AI capability boundaries
- Inform future delegation decisions with concrete data
- Satisfy internal audit and compliance requirements
Part Seven: Comparison with Existing Solutions — Why Traditional Approaches Fall Short
7.1 Limitations of Traditional Chat AI
Traditional chat AI (such as standard chat interfaces for large language models) has systematic deficiencies in controllability:
- Extremely low behavioral visibility: Users can only see the final text output, with no window into the AI’s thinking process or intermediate steps
- Nonexistent permission control: Users cannot limit what the AI can do — although the AI does not have much “doing” capability anyway, since it primarily generates text
- Limited real-time interruption: Can only stop text generation, and after stopping, cannot precisely control where to resume
- Zero rollback capability: Dissatisfaction means regeneration; there is no partial undo or selective rollback
Traditional chat AI is acceptable precisely because its “capability boundary” is naturally safe — it only generates text and does not directly impact the real world. But when AI evolves into agents capable of real-world operations, this model without safety mechanisms becomes entirely untenable.
7.2 Limitations of Low-Code/RPA Platforms
Low-code and RPA (Robotic Process Automation) platforms are considerably better than chat AI in terms of controllability, but they still have notable shortcomings:
- Visibility limited to flowcharts: Users can see predefined flowcharts, but when actual execution deviates from the flowchart, transparency drops sharply
- Overly rigid permission control: Permissions are typically bound within process definitions and cannot be flexibly adjusted at runtime
- Limited real-time interruption: Can pause the entire process but cannot finely control post-pause recovery — restart from scratch, continue from the breakpoint, or skip the current step
- Near-zero rollback capability: Most RPA platforms only offer “re-execute” functionality, not true rollback. Rollback requires the system to undo already-executed operations, not merely re-run the process
7.3 Comparison Summary
| Dimension | Traditional Chat AI | Low-Code/RPA | DesireCore |
|---|---|---|---|
| Behavioral visibility | Output text only | Flowchart level | Real-time per-step transparency |
| Permission control | None | Bound to fixed processes | Flexible three-tier classification |
| Real-time interruption | Stop generation | Pause process | Any operation level |
| Rollback capability | None | Re-run process | Four-level granular rollback |
| Execution audit | None | Process logs | Structured receipts |
| Trust mechanism | Relies on reputation | Relies on process design | Systematic guarantee |
DesireCore’s three-layer control architecture is not an incremental improvement over traditional approaches. It is a fundamental paradigm shift — from “limiting AI capabilities to ensure safety” to “empowering users with complete control to build trust.”
Part Eight: Controllability in Real Scenarios — From Theory to Practice
8.1 Scenario One: Contract Review
Task: An AI agent reviews a 50-page supplier contract, identifies risky clauses, and proposes modifications.
Visibility in action:
- Users can see in real time which section of the contract the AI is reading
- When the AI flags a risky clause, users can see the reasoning (referenced regulations, industry standards, risk assessment logic chain)
- When the AI compares similar contracts, users can see which contracts it selected as reference samples
Controllability in action:
- Users set “AI may flag risks but cannot directly modify the contract text”
- The “final risk rating” step is set as a Human Gate — the AI provides a preliminary rating, the user confirms or adjusts before the final report is generated
- If the AI needs to query external legal databases to verify a clause, it requires per-query user authorization
Reversibility in action:
- If the user finds that the AI’s risk assessment for a particular clause is overly aggressive (flagging a normal clause as high-risk), they can undo that clause’s assessment and have the AI re-evaluate with adjusted parameters
- If the entire report’s tone does not match expectations, the user can roll back to the session start, adjust the review instructions, and restart
8.2 Scenario Two: Financial Data Processing
Task: An AI agent organizes the month’s accounts receivable data, generates a collection priority list, and drafts collection emails.
Visibility in action:
- During data cleansing, users can see how the AI handles each record — retained, corrected, or flagged as anomalous
- During priority ranking, the AI displays the ranking algorithm’s core factors (aging, amount, customer credit rating, historical payment records) and their respective weights
- During email drafting, users can see the email templates the AI referenced and the personalized adjustments made for each client
Controllability in action:
- Data reading is set to allow (low-risk operation)
- Data corrections are set to ask (users confirm whether each correction is reasonable)
- Actually sending emails is set to deny (AI only drafts; it does not send)
- The “flag receivables exceeding 1 million” step is set as a Human Gate — large-amount collection strategies must be confirmed by a human
Reversibility in action:
- If a particular client’s position in the priority list is unreasonable, the user can undo that client’s scoring, manually adjust it, and have the AI re-rank
- If the entire collection strategy needs reorientation (e.g., from “sort by aging” to “sort by recovery probability”), the user can roll back to the strategy-setting stage
8.3 Scenario Three: Code Review and Bug Fixing
Task: An AI agent reviews code changes in a Pull Request, identifies potential bugs, and proposes fixes.
Visibility in action:
- Users can see which file changes the AI is currently analyzing
- When the AI flags a potential bug, it displays its complete reasoning chain — from code logic analysis to boundary condition testing to specific failure scenarios
- When the AI calls testing tools for verification, users can see the test inputs, outputs, and comparison results
Controllability in action:
- Code reading and analysis is set to allow
- Writing test cases is set to allow
- Actually modifying source code is set to ask — the AI must present its modification plan, and the user approves before execution
- Merging to the main branch is set to deny — code merges must be performed by human developers
Reversibility in action:
- If one of the AI’s fix proposals introduces a new issue, the user can precisely undo that single modification (Patch level) while keeping other fixes
- If the entire review methodology needs adjustment (e.g., the AI focused too much on code style and overlooked logic errors), the user can roll back to the review start, adjust the focus areas, and restart
8.4 Scenario Four: Customer Service Ticket Processing
Task: An AI agent processes the day’s customer tickets — classifies them, assigns priorities, auto-replies to simple questions, and escalates complex issues.
Visibility in action:
- Each ticket’s classification process is transparent — why the AI categorized this ticket as “technical issue” rather than “account issue”
- Auto-reply content is fully displayed before sending, including referenced knowledge base entries
- Escalation decision logic is clearly visible — why the AI deemed this issue worthy of escalation
Controllability in action:
- Ticket classification and priority assignment are set as flexible steps — AI judges autonomously, but results are visible
- Auto-replies are set as Human Gates — template responses for simple issues are sent after confirmation; after a period of validation, they can be downgraded to allow
- Complex issue escalation paths are set as solidified steps — executed strictly according to predefined escalation rules
- Refund operations are set to deny — AI cannot approve refunds on its own
Reversibility in action:
- If a ticket is incorrectly classified, the classification can be undone step by step and reassigned
- If a batch of tickets’ priority strategy needs adjustment, it can be rolled back turn-by-turn to before the strategy was set
Part Nine: Security Governance — System-Level Safety Guarantees
9.1 Four-Level Risk Classification System
DesireCore’s security governance does not rely solely on user-configured permissions. It also includes a built-in four-level risk classification system that automatically assesses the risk level of each operation:
- Level 1 (Low Risk): Read-only operations, format conversions, information queries, and other operations with no side effects. AI can self-approve and execute.
- Level 2 (Low-Medium Risk): Creating new content, generating reports, and other operations with limited impact scope. Typically auto-approved, but the system records detailed logs.
- Level 3 (Medium-High Risk): Modifying existing data, calling external services, sending communications, and other operations that may produce material impact. User confirmation required by default.
- Level 4 (High Risk): Deleting data, executing transactions, modifying permission settings, and other irreversible or high-impact operations. Even if the user sets them to allow, the system will trigger secondary confirmation.
This risk classification system works in tandem with user-defined permission rules, forming a dual safety guarantee — even if a user forgets to set restrictions on a particular operation, the system’s risk classification provides a safety net.
9.2 Audit Trail
Every operation in DesireCore is comprehensively recorded in an audit log. Audit logs are tamper-proof, precisely timestamped, and include full context. These logs serve not only post-incident investigation but also supply data to the receipt system.
For enterprise users, a complete audit trail means:
- Meeting industry compliance requirements (finance, healthcare, legal, and other regulated industries)
- Supporting internal audits and security reviews
- Precisely pinpointing causes when issues arise
- Providing data to optimize AI usage strategies
9.3 Data Security
DesireCore employs a local-first data storage strategy. User data, agent configurations, conversation histories, and operation logs are stored on the user’s local device by default, not uploaded to the cloud. For scenarios requiring cloud collaboration, data is encrypted during both transmission and storage.
This design choice reflects DesireCore’s core philosophy on security: users’ data should be under users’ control. We do not need your data to improve our models, nor do we need it to support our business model. Your data is your data.
Conclusion: Trust Is Not Promised — It Is Designed
Let us return to the core question posed at the beginning of this article: users’ biggest barrier is not “whether AI can handle the job” but “whether I dare let it.”
DesireCore’s three-layer control architecture — Visible, Controllable, Reversible — is the systematic answer to this question:
Visibility lets you know at all times what the AI is doing and why, eliminating the unease of a black box. Like an employee who proactively works with their door open, earning trust through transparency.
Controllability lets you precisely define the AI’s behavioral boundaries — neither over-restricting its capabilities (in which case you might as well do it yourself) nor allowing it to act without constraints (in which case you cannot afford the consequences). Like a well-designed access control system that lets the right people do the right things within the right scope.
Reversibility eliminates the fear of “no undo,” emboldening you to let AI experiment and explore, because you know the worst outcome is simply pressing “undo.” Like a safety net — only with it in place do you dare walk the tightrope.
None of the three can be missing. Together, they form a complete trust system that transforms AI from “I know it is powerful but I dare not use it” to “I can confidently delegate tasks to it.”
Trust cannot be established with a single statement of “our AI is safe.” Trust is built incrementally through verifiable actions, reliable safeguards, and traceable records. It is a systems engineering challenge that must be considered from the very foundation of product architecture.
DesireCore has chosen this harder but more correct path. Because we believe that only when users truly dare to use AI can its potential be fully unlocked. And the only way to make users dare is to put control in their hands — not through verbal promises, but through guarantees written into the code.
This is the significance of the three-layer control system. It is not merely a feature list; it is a product philosophy: technology’s power should be governed by its users, not a source of their anxiety.
If this philosophy resonates with you, we invite you to download DesireCore and experience the trust that three-layer control provides firsthand. Because the most compelling proof is always personal experience.
