Smarter with Every Use: DesireCore's Self-Evolution and Memory System Explained
Smarter with Every Use: DesireCore’s Self-Evolution and Memory System Explained
Introduction: Why Your AI Assistant Never “Grows Up”
Imagine this scenario: you’ve been chatting with an AI assistant for three months. You’ve told it you prefer concise reporting styles, reminded it about your company’s special contract review process, and corrected its data analysis preferences multiple times. Yet when you open the conversation window today, it still writes your weekly report in a verbose format, still doesn’t remember your company’s contract clause priorities, and still creates data visualizations you don’t like.
This isn’t a problem with any single product — it’s an industry-wide predicament.
The way traditional AI assistants work is fundamentally “stateless.” Every conversation feels like a first meeting. They possess vast general knowledge bases and can answer all kinds of questions, but they can’t remember who you are, what you prefer, or what you asked them to do last time. Even products that have introduced so-called “conversation history” features merely concatenate past chat logs mechanically into the context — they haven’t truly “understood” or “internalized” that information.
It’s like having an employee who loses their memory every day. No matter how intelligent they are, no matter how extensive their expertise, if they wake up every morning with no recollection of what happened yesterday, they can never become a truly capable assistant. You’re forced to repeat the same instructions, explain the same preferences, and correct the same mistakes over and over again.
The deeper issue is that this “amnesia” isn’t just a memory deficit — it’s a growth deficit. A good human assistant doesn’t just remember what you’ve said; they learn from every task, gradually understand your working style, and even proactively suggest improvements. Traditional AI assistants have virtually zero capability in this regard.
This is the fundamental problem DesireCore set out to solve.
Our core philosophy is simple: A truly useful AI agent should be like a good employee — they might not know anything on their first day, but three months later, they can handle things independently.
This isn’t a marketing slogan — it’s a complete technical system. In this article, we’ll take a deep dive into DesireCore’s self-evolution mechanism and memory system, explaining how it achieves “smarter with every use” — and equally important, how it maintains safety and control throughout this process.
Part One: The Growth Journey of a Digital Companion — Four Growth Stages
Before diving into specific technical mechanisms, let’s outline the typical growth trajectory of a DesireCore agent. This will help you build an intuitive understanding of what “self-evolution” actually means in practice.
Stage One: Getting Acquainted (Days 1–3)
When you first create a DesireCore agent, it’s like a newly hired employee. It possesses solid foundational capabilities — language understanding, text generation, logical reasoning, code writing, and more — but it knows nothing about you.
During this stage, the agent’s primary job is to “listen” and “observe.” It notices your communication style: Do you prefer detailed explanations or concise conclusions? Do you favor formal language or a casual tone? What depth of response do you typically expect when asking questions?
At the same time, it’s building an initial user profile. Your professional background, area of expertise, frequently used tools, work habits — this information is gradually recorded and organized.
The agent at this stage is still somewhat “raw.” Its responses may be overly generic, occasionally deliver formats that don’t quite match your expectations, and sometimes require extra explanation from you to accurately understand your needs. But this is normal — just like a new employee needs time to adjust to their work environment.
Stage Two: Adaptation (Days 4–14)
After the first few days of interaction, the agent begins to demonstrate noticeable adaptation.
The most visible changes appear in communication style. If you consistently trim the agent’s lengthy responses before using them, it gradually learns to provide more concise content. If you frequently follow up its analytical reports with “so what should we actually do,” it starts proactively appending action recommendations after its analyses.
During this stage, you’ll notice the number of corrections and explanations you need to provide drops significantly. The agent begins remembering your preference settings — your preferred document format, commonly used terminology, and quality standards for specific tasks. It’s no longer a generic AI tool but is beginning to become “your” AI assistant.
More importantly, the agent starts forming an understanding of your work patterns during this stage. It notices that you typically handle emails on Mondays, prepare weekly reports on Wednesdays, and compile data summaries at month’s end. It learns that you have different standards for different types of tasks — some tasks you pursue perfection on, while others just need to be done quickly.
Stage Three: Collaboration (Days 15–60)
This is the stage where changes become most pronounced. The agent is no longer just passively responding to your instructions — it begins demonstrating genuine “collaboration” capabilities.
It proactively makes suggestions based on its understanding of your work patterns. For example: “I’ve noticed the data analysis section in your last three reports needed rework. Would you like me to adjust the default analysis framework?” Or: “Last time you reviewed a similar contract, you focused on the indemnification clauses. Want me to extract the indemnification clauses first this time?”
During this stage, the agent’s knowledge base also continuously enriches. Through installing skill packs and connecting MCP tools, its capability boundaries keep expanding. An agent that initially could only handle text may have already learned to connect to your project management tool, read your database, and call your internal APIs.
Collaborative evolution in team scenarios also begins to take effect. If you and your colleagues share an agent, it learns team-level knowledge and standards while maintaining an understanding of each member’s personal preferences.
Stage Four: Mastery (60+ Days)
By this stage, the agent has truly become your capable assistant. It deeply understands your field of work, is familiar with all your preferences and habits, can handle complex multi-step tasks, and can even gently remind you when you make mistakes.
An agent in the mastery stage works with almost no additional instructions needed. You say “help me prepare for Monday’s client meeting,” and it knows to check your calendar, organize the latest progress on relevant projects, prepare a presentation outline in your preferred format, and remind you of concerns the client raised in the last meeting.
But “mastery” doesn’t mean “stopped growing.” The agent continues to optimize its working methods, adapting to your ever-changing needs. When your work focus shifts, team structure adjusts, or business direction changes, it correspondingly adjusts its knowledge structure and behavioral patterns.
The progression through these four stages isn’t linear or rigid. Different task domains may evolve at different speeds, your active teaching can significantly accelerate growth in certain areas, and the agent may learn faster in some domains than others. But the overall trend is clear: Over time and with accumulated interactions, the agent becomes better at understanding you and more useful.
Part Two: The Three-Layer Evolution Mechanism in Detail
DesireCore agents getting “smarter with every use” isn’t magic — it’s built on a carefully designed three-layer evolution mechanism. Each layer addresses a different type of learning problem, and the three work together to form complete evolutionary capability.
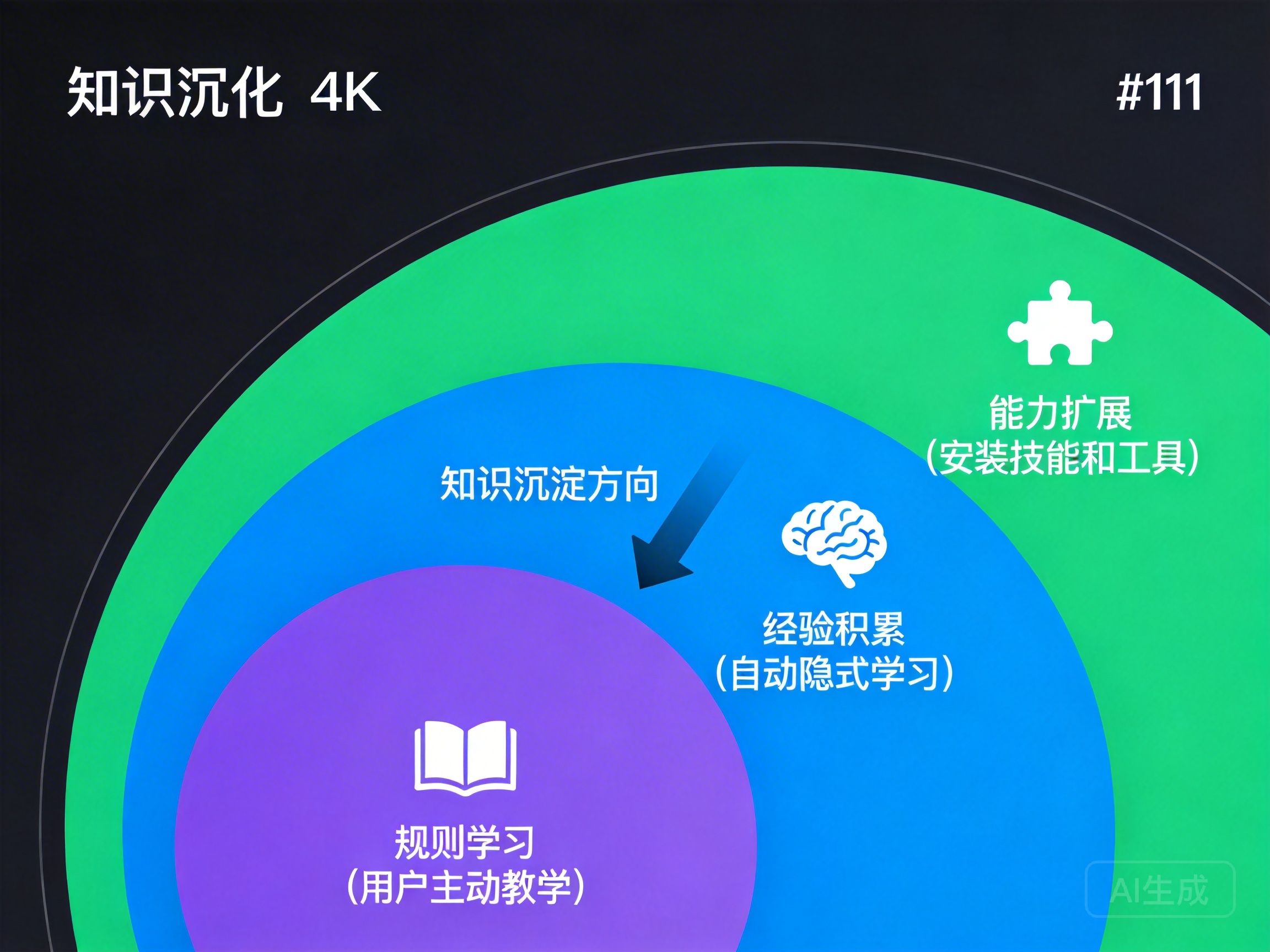
Layer One: Rule Learning (Explicit Teaching)
Rule learning is the most direct form of evolution. You actively tell the agent how to do things through conversation, and it converts those instructions into persistent behavioral rules.
How It Works:
When you tell the agent “from now on, use this format when writing my weekly reports,” or “when reviewing contracts, prioritize checking penalty clauses and IP ownership,” the agent parses these instructions into structured rules. But there’s a key design choice here: rules don’t take effect immediately.
The system generates a modification proposal (diff) that clearly shows the rules to be added or modified. You can review this proposal, confirm it accurately reflects your intent, and then approve it. Rules only officially take effect after your confirmation.
The purpose of this design is transparency and controllability. AI can sometimes misinterpret natural language — you say “be more concise,” and it might interpret that as “give only conclusions without process,” when you actually meant “the process can be simplified but not omitted.” Through the modification proposal mechanism, you can catch and correct these interpretation gaps before rules take effect.
Typical Scenarios:
Scenario One: Weekly Report Format Customization
You tell the agent: “Our team’s weekly report format is like this — first write what was completed this week using a numbered list; then write next week’s plans, also as a numbered list; finally write issues needing coordination, or ‘None’ if there aren’t any. Each item should be no more than two lines.”
The agent generates a rule: “When the user requests a weekly report, use the following template: 1) This week’s completed items (numbered list, max two lines each); 2) Next week’s work plan (numbered list, max two lines each); 3) Issues requiring coordination (numbered list or ‘None’).”
After you confirm, this rule is persistently stored. From then on, every time you say “help me write a weekly report,” the agent automatically applies this format without you needing to explain again.
Scenario Two: Contract Review Rules
You tell the agent: “When reviewing contracts, focus on these clauses: whether the penalty ratio exceeds 30% of the total contract value; whether there are exclusivity clauses for IP; whether the non-compete period exceeds two years; whether the payment cycle exceeds 60 days. If any of these don’t meet the standard, flag it with a red warning.”
These rules are precisely recorded and automatically applied during every contract review. More importantly, as you review more contracts and provide feedback, these rules can be gradually refined and supplemented.
Rule Management:
Over time, you may accumulate numerous rules. DesireCore provides complete rule management functionality: you can view all existing rules, modify existing rules, delete rules that are no longer needed, set rule priorities, and specify rule applicability scopes (for example, a rule that only applies when handling a specific type of task).
Layer Two: Experience Accumulation (Implicit Learning)
If rule learning is “you teach it,” then experience accumulation is “it learns on its own.” This is one of DesireCore agents’ most distinctive capabilities — automatically observing, analyzing, and learning during everyday interactions without requiring you to deliberately teach it.
Three Major Implicit Learning Mechanisms:
Mechanism One: Automatic User Profile Updates
The agent continuously observes your behavioral patterns and automatically updates its internal user profile. This profile covers multiple dimensions:
- Communication preferences: Your preferred response length, tone, format, and level of detail
- Professional background: Your domain knowledge level, commonly used terminology, and tech stack
- Work habits: Your work rhythm, task handling patterns, and decision-making style
- Quality standards: Your requirements for different types of content — some content you demand precision down to every number, others you only care about the general direction
This learning is completely automatic. You don’t need to fill out any questionnaires or configure any options. The agent analyzes every interaction — your questioning style, your reactions to responses, your edits and additions — to continuously optimize its understanding of you.
For example: if you consecutively extract only the conclusion section from several lengthy analyses the agent provides, the agent gradually realizes you prefer concise output for this type of task. Next time, it might give you a brief conclusion first, then ask if you’d like to see the detailed analysis.
Mechanism Two: Post-Task Review
After completing each task, the agent conducts a “review” in the background. This review process includes:
- Result evaluation: Was the task successfully completed? Was the user satisfied? Were multiple revisions needed to meet expectations?
- Process analysis: Which steps were executed efficiently? Where did deviations occur? What caused them?
- Experience extraction: What can be learned from this task? Which experiences can be applied to similar future tasks?
- Capability gap identification: Did processing this task expose any capability deficiencies? If so, how can they be addressed?
Review results are integrated into the agent’s experience repository. This means that even if you never actively teach it, it improves itself with every task.
Mechanism Three: Periodic Self-Assessment
Beyond passive reviews, the agent also proactively conducts periodic self-assessments. This self-assessment process examines the agent’s current knowledge structure and behavioral patterns, identifying possible directions for improvement.
For instance, the agent might discover it frequently needs to consult external materials when processing your legal documents, suggesting its legal domain knowledge may need strengthening. It might proactively suggest you install a legal knowledge skill pack or propose connecting to a legal database tool.
This self-assessment mechanism ensures the agent’s evolution includes not just passive adaptation but also proactive self-improvement.
Layer Three: Capability Expansion
The first two layers of evolution address “doing better within existing capabilities.” The third layer is about “expanding capability boundaries” — enabling the agent to do things it couldn’t do before.
Three Ways to Expand Capabilities:
Method One: Installing Skill Packs
Skill packs are pre-packaged knowledge and capability modules. DesireCore offers a rich skill pack marketplace covering various professional domains and work scenarios.
For example, a “Financial Analysis Skill Pack” might include:
- Common financial metric calculation methods
- Financial statement interpretation frameworks
- Industry benchmarking analysis templates
- Financial risk assessment rules
After installing a skill pack, the agent gains the corresponding professional capabilities and can invoke this knowledge and methodology in relevant tasks.
Method Two: Connecting MCP Tools
MCP (Model Context Protocol) is DesireCore’s tool integration standard. Through MCP, agents can connect to various external tools and services: databases, project management systems, code repositories, communication platforms, enterprise internal systems, and more.
Each new MCP tool connection gives the agent a new “arm” — it can not only think and converse but also actually operate these tools to complete tasks.
Method Three: Agent Self-Proposal
This is the most advanced form of capability expansion. When the agent discovers it lacks a certain capability during work, it proactively makes suggestions to you.
For example: “I’ve noticed you frequently need to handle data visualization tasks recently, but I can currently only generate basic text tables. Would you consider connecting a data visualization tool? I recommend XXX — it can generate interactive charts directly in our conversation.”
These self-proposals require your explicit consent before execution. The agent will never install any skill packs or connect any tools on its own — it simply makes suggestions based on its understanding of your needs, and the final decision always rests with you.
Synergy Among the Three Layers:
The three layers of evolution don’t operate independently — deep synergy exists between them. Rule learning provides clear behavioral guidelines, experience accumulation continuously optimizes execution, and capability expansion broadens available tools and knowledge when needed.
For example: you teach the agent a rule — “always begin client emails with ‘Dear Mr./Ms. XX’” (rule learning). In practice, the agent observes that you use more familiar greetings with certain long-term clients and automatically adjusts its greeting strategy for different clients (experience accumulation). Later, it suggests connecting your CRM system to obtain accurate client information and communication history, further enhancing email personalization (capability expansion).
Part Three: Four Evolution Modes — Implicit, Explicit, Review, and Collaborative
Building on the three-layer evolution mechanism, DesireCore defines four specific evolution modes. Each mode has different triggers and confirmation requirements, suited to different scenarios.
Mode One: Implicit Learning
| Property | Description |
|---|---|
| Trigger | Automatic |
| Confirmation Required | No |
| Use Case | Behavioral pattern learning during daily interactions |
Implicit learning is the most “seamless” evolution mode. It operates automatically during every interaction, requiring no extra action from you and never interrupting your workflow with confirmation dialogs.
This mode primarily learns your behavioral patterns and preferences. It doesn’t change the agent’s core rules or capability configuration — it only fine-tunes its interaction style, such as response detail level, language style, and task prioritization.
The reason no confirmation is needed is that these adjustments are low-risk and incremental. Each adjustment is small in magnitude and reversible. If any adjustment feels off, you simply provide feedback (like “that was too brief, give me more detail”), and the agent adjusts accordingly.
The cumulative effect of implicit learning is significant. Individually, each fine-tuning is barely noticeable; but after a few weeks, you’ll clearly feel the agent has become “more in tune with you” — its responses better match your expectations, and you need to make corrections and explanations far less frequently.
Technical Details:
The core of implicit learning is a continuously running observe-analyze-adjust loop. The agent collects multi-dimensional signals during every interaction:
- Direct signals: Your explicit feedback — approval, rejection, modification suggestions
- Indirect signals: Your behavioral patterns — Did you use the agent’s output in full? What modifications did you make? Did you follow up for more details?
- Contextual signals: Current task type, temporal context, overall conversation tone
These signals are analyzed collectively to form a set of fine-tuning instructions applied to the agent’s behavioral parameters. The entire process occurs in the background without affecting real-time interaction performance.
Mode Two: Explicit Teaching
| Property | Description |
|---|---|
| Trigger | User-initiated teaching |
| Confirmation Required | Yes |
| Use Case | Establishing clear rules and standards |
Explicit teaching is the process of you actively “training” the agent. When you need the agent to follow specific rules, procedures, or standards, you can tell it directly through conversation.
Unlike implicit learning, explicit teaching involves changes that are typically more significant and definitive. It may alter the agent’s overall behavior on certain tasks, not just fine-tune. Therefore, explicit teaching requires your explicit confirmation.
How the Confirmation Mechanism Works:
When you give a teaching instruction, the agent goes through the following steps:
- Understanding and parsing: Analyzes your instruction to understand what rule you want to establish
- Conflict detection: Checks whether the new rule conflicts with existing rules
- Proposal generation: Generates a modification proposal (diff) clearly showing the intended changes
- User confirmation: Presents the proposal for your review and confirmation
- Rule application: Officially applies the rule to the agent’s behavioral system after your confirmation
If conflicts are detected, the agent explicitly identifies the conflict points and suggests resolutions — whether to override the old rule, modify the new rule, or set conditions to distinguish the applicability of both rules.
Best Practices for Teaching:
To make explicit teaching more effective, we recommend following these principles:
- Be specific, not vague: “Use tables for data in reports” is more effective than “make my reports look good”
- Example-driven: Including an example you’re satisfied with is clearer than pure text descriptions
- Teach in steps: Break complex rules into several sessions, teaching one aspect at a time
- Provide timely feedback: Test immediately after teaching and correct any issues right away
Mode Three: Review-Based Evolution
| Property | Description |
|---|---|
| Trigger | Automatically after task completion |
| Confirmation Required | Partial (significant changes require confirmation) |
| Use Case | Distilling experience from practice |
Review-based evolution occurs after each task is completed. The agent reviews the entire task execution process, analyzing what went well and what could be improved.
What makes this mode unique is its “partial confirmation” mechanism. Not all review conclusions require your confirmation — for low-risk experience summaries (like “this user prefers bar charts over pie charts for data analysis tasks”), the agent automatically adds them to its experience repository; for significant findings that might affect core behavior (like “this user seems to want a more formal tone in all external communications”), the agent consults you first.
Depth and Breadth of Reviews:
Reviews aren’t simply a “good/bad” binary. The agent’s review process contains multiple levels:
- Execution-level review: Were the specific operational steps optimal? Is there a more efficient implementation?
- Strategy-level review: Was the overall problem-solving approach correct? Were any angles missed?
- Communication-level review: Was communication with the user smooth? Was information conveyed clearly?
- Knowledge-level review: What knowledge was used in this task? What knowledge was lacking?
Results from each level are converted into concrete improvement measures and persisted in the agent’s experience system.
Review Timing and Frequency:
Not every interaction triggers a deep review. The system determines review depth based on task complexity, importance, and whether deviations occurred during execution:
- Simple tasks (like answering a factual question): Lightweight review, mainly recording user feedback
- Medium tasks (like writing a document): Standard review, analyzing the execution process and user modification feedback
- Complex tasks (like completing a multi-step analysis project): Deep review, comprehensively examining strategy, execution, communication, and knowledge
Mode Four: Collaborative Evolution
| Property | Description |
|---|---|
| Trigger | Multi-user interaction |
| Confirmation Required | Yes |
| Use Case | Accumulation and sharing of team knowledge |
Collaborative evolution is DesireCore’s evolution mode for team scenarios. When multiple users share the same agent, the agent needs to balance team consensus with individual preferences.
How Collaborative Evolution Works:
In team scenarios, the agent maintains two levels of knowledge:
- Team shared knowledge: Rules, processes, and standards agreed upon by all team members — such as company document templates, coding standards, and approval workflows
- Personal preference knowledge: Each member’s individual preferences — for example, A prefers detailed explanations while B prefers concise bullet points
When the agent learns something from one member’s interactions that might be valuable for the entire team, it initiates a “knowledge proposal”:
“In my collaboration with Member A, I discovered a more efficient code review process. This process might be helpful for the whole team. Would you like to add it to the team’s shared knowledge?”
This proposal requires confirmation from the appropriate authority (typically the team administrator or all relevant members) before taking effect.
The Value of Collaborative Evolution:
The greatest value of collaborative evolution lies in the “multiplication effect of knowledge.” In traditional work methods, one person’s experience and best practices are difficult to efficiently propagate to the entire team. Through the agent’s collaborative evolution, one person’s discovery can be quickly distilled, validated, and shared with all relevant members.
For example, a senior team member teaches the agent an efficient data cleaning method. Through collaborative evolution, this method can be automatically recommended to other team members facing similar tasks, without the senior member needing to personally guide each one.
Summary Comparison of the Four Modes:
| Mode | Trigger | Confirmation | Learning Speed | Learning Depth | Use Case |
|---|---|---|---|---|---|
| Implicit Learning | Automatic | No | Gradual | Shallow fine-tuning | Daily preference adaptation |
| Explicit Teaching | User-initiated | Yes | Immediate | Deep rules | Establishing clear standards |
| Review Evolution | Post-task | Partial | Medium | Medium-deep | Experience accumulation |
| Collaborative Evolution | Multi-user | Yes | Medium | Team-level | Team knowledge sharing |
These four modes together form a complete evolutionary ecosystem. In practice, they often operate simultaneously and complement each other. In a typical work scenario, implicit learning continuously fine-tunes, explicit teaching establishes rules at key points, review evolution distills experience after each task, and collaborative evolution aggregates wisdom at the team level.
Part Four: Three-Domain Memory Architecture — Core, Relational, and Shared Memory
Evolution requires memory as its foundation. If evolution mechanisms are the “engine” of agent growth, then the memory system is the “fuel” for that engine.
Before diving into the memory system, there’s an important concept to clarify: DesireCore’s memory system is fundamentally different from ordinary chat logs.
Chat logs are raw, unprocessed conversation history — they chronologically record every message between you and the AI. They are passive, linear, and indiscriminate.
A memory system is a processed, organized, and structured knowledge framework — it not only records information but, more importantly, understands relationships between pieces of information, extracts the essence of information, and organizes it in a logical structure. It is active, multi-dimensional, and selective.
It’s like the difference between a diary and brain memory. A diary records what you did each day, but brain memory integrates these experiences into skills, knowledge, and intuition, helping you better face future challenges.
DesireCore’s memory system adopts a “three-domain architecture,” consisting of three interconnected but functionally distinct memory domains:
Domain One: Core Memory
Core memory stores the most fundamental and enduring information about the user and their tasks. This information forms the “skeleton” of the agent’s understanding of the user.
What Core Memory Contains:
- User basic information: Occupation, industry, role, job responsibilities
- Personal preferences: Communication style, work habits, quality standards
- Professional knowledge graph: User’s areas of expertise, knowledge level, commonly used tools
- Core rules: Persistent rules established through explicit teaching
- Goals and values: Work objectives, value orientations, decision-making principles
Core memory is characterized by high stability and low change frequency. Once information is stored in core memory, it typically remains unchanged for a long time. Of course, it’s not immutable — if the user’s situation changes substantially (such as changing jobs or adjusting responsibilities), core memory updates accordingly.
Accessing and Managing Core Memory:
Core memory is completely transparent to the user. You can view the agent’s “core understanding” of you at any time and confirm whether this information is accurate. If you find any information that’s incorrect or outdated, you can directly modify or delete it.
This transparency is an important embodiment of DesireCore’s design philosophy: AI’s understanding of you shouldn’t be a black box. You have the right to know how AI “sees you,” and you have the right to correct its misconceptions.
Domain Two: Relational Memory
Relational memory stores “relational” information accumulated through the agent’s interactions with the user. If core memory is a “static portrait,” then relational memory is the “dynamic relationship.”
What Relational Memory Contains:
- Interaction history summaries: Not raw chat logs, but distilled interaction highlights — how many times different types of tasks were handled, success rates, and common communication patterns
- Preference evolution trajectory: The history of changes in user preferences — for example, a user who initially preferred detailed reports but later shifted to preferring concise summaries
- Task experience repository: Experiences distilled from past tasks — which methods work best in which scenarios, which types of issues need special attention
- Feedback patterns: The user’s feedback habits — Under what circumstances do they tend to give positive feedback? When do they become dissatisfied? How do they express dissatisfaction?
- Trust level assessment: The agent’s self-evaluation of its performance in different domains — In which tasks does the user highly trust it? In which areas does it still need more proof?
Relational memory is characterized by strong dynamism and continuous evolution. It updates and enriches with every interaction.
The Value of Relational Memory:
Relational memory enables the agent to be “context-aware” — not just understanding the context of the current conversation, but understanding the context of your entire working relationship.
For example, the first time you ask the agent to help write an important proposal, it might be extra cautious, confirming every key point with you. But after several successful collaborations, relational memory records that your trust level in its proposal writing is already high, and it can more confidently complete most of the work independently, only consulting you at a few critical decision points.
This adaptive behavior based on relationship history is one of the key features distinguishing DesireCore agents from traditional AI assistants.
Domain Three: Shared Memory
Shared memory is a memory domain designed for team and organizational scenarios. It stores knowledge and standards shared among team members.
What Shared Memory Contains:
- Team standards: Team workflows, communication norms, coding standards, document templates, etc.
- Organizational knowledge base: Company policies, product information, customer information, industry knowledge, etc.
- Best practices: Validated effective methods and work patterns
- Project context: Background information, progress, key decisions, and milestones for ongoing projects
Shared memory is characterized by multi-source input and access control. Any team member can potentially contribute new knowledge to shared memory, but contributions must go through appropriate approval processes (referring to the collaborative evolution mode discussed earlier). Additionally, different content in shared memory may have different access permissions — some information is open to all members, while some is viewable only by specific roles.
How the Three Domains Work Together:
The three memory domains aren’t isolated information silos — rich interactions exist between them.
When the agent processes a task, it simultaneously extracts relevant information from all three memory domains:
- From core memory: Gets the user’s basic preferences and rules
- From relational memory: Gets experience from handling similar tasks and the user’s feedback patterns
- From shared memory: Gets team standards and relevant organizational knowledge
These three layers of information are integrated to form a comprehensive task processing context. The agent plans and executes tasks based on this context, ensuring output that conforms to both the user’s personal preferences and the team’s standard requirements.
Information Flow Between Domains:
Memory information can also flow between the three domains. For example:
- A personal experience (relational memory) proven to be universally valuable to the team can be elevated to shared memory
- A team standard (shared memory) customized by a user has its personalized version stored in core memory
- A repeatedly occurring interaction pattern (relational memory) may be distilled into a core rule (core memory)
This cross-domain information flow ensures overall consistency and optimal efficiency of the memory system.
Part Five: Auto Dream — Memory Consolidation Inspired by Human Sleep
So far, we’ve discussed how agents learn (evolution mechanisms) and where learned knowledge is stored (memory system). But there’s a key question left unanswered: What happens when memories keep accumulating?
This is a real and pressing issue. As usage time grows, agents accumulate massive amounts of memory data — including user preferences, task experiences, interaction details, and more. If this data is allowed to grow indefinitely, it not only increases storage costs but also affects the agent’s operational efficiency — it needs to search through an ever-larger memory repository for relevant information, which slows response times and reduces information retrieval accuracy.
The traditional solution is crude: set a time window or capacity limit, and delete old memories exceeding the threshold. But this “hard deletion” causes valuable historical information to be lost, and the agent might suddenly “forget” certain user preferences or habits.
DesireCore has proposed an entirely new solution: Auto Dream.
The Inspiration: Human Sleep and Memory
Auto Dream’s design draws inspiration from neuroscience research on human sleep mechanisms.
Scientists have discovered that the human brain during sleep isn’t simply “shutting down to rest” — it’s performing extensive memory processing work:
- Memory consolidation: Integrating scattered information acquired during the day into structured long-term memories
- Pattern extraction: Extracting common patterns and rules from numerous experiences
- Irrelevant information cleanup: Weakening and clearing unimportant details
- Knowledge structuring: Connecting new knowledge with existing knowledge to form more complete knowledge networks
The key point is: The human brain during sleep isn’t “deleting” memories but “consolidating” them. It condenses masses of scattered, specific experiences into refined knowledge and patterns. You might not remember the details of every lunch you had last month, but you clearly know what you like to eat.
Auto Dream simulates exactly this process.
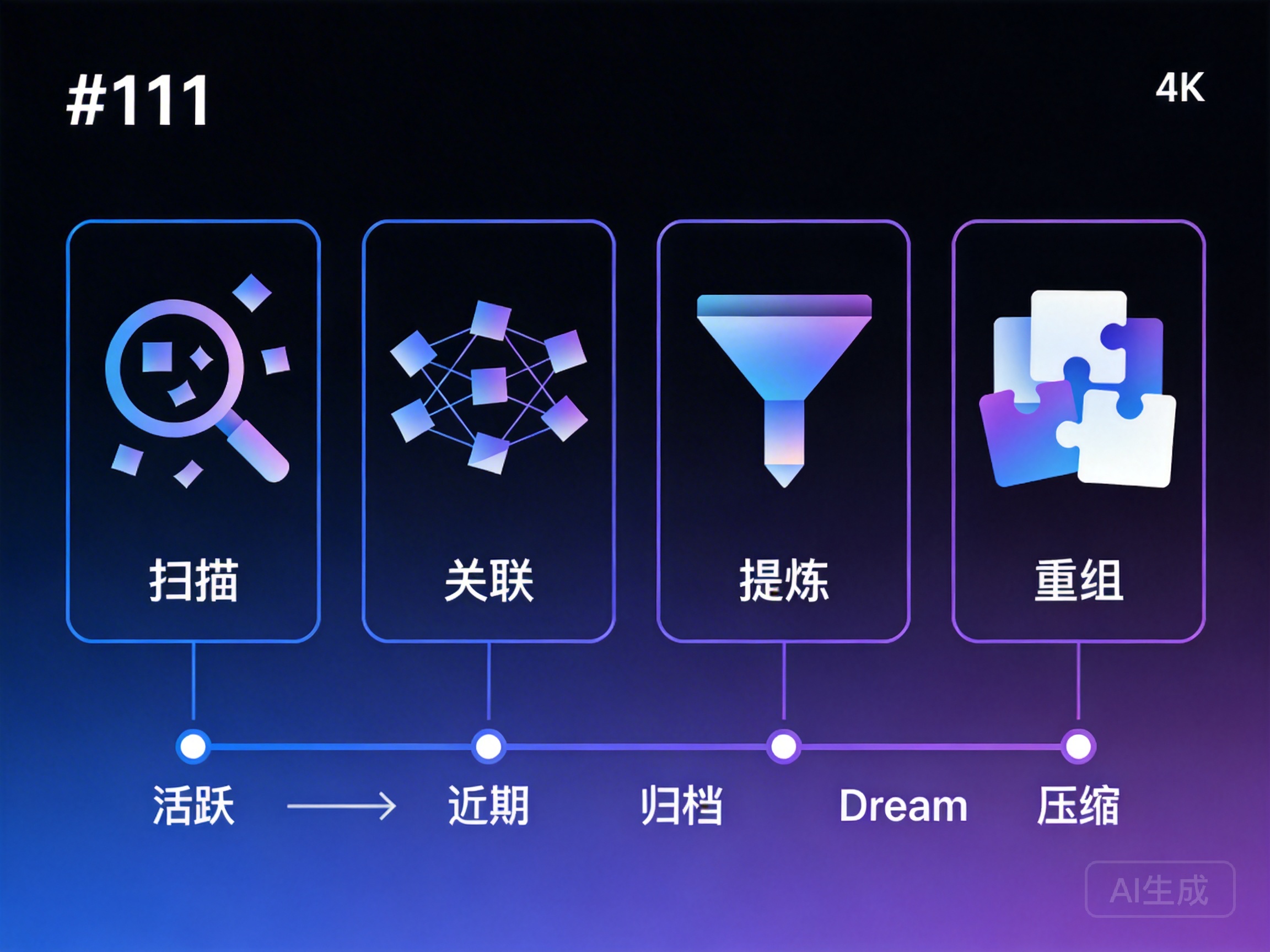
The Four Stages of Auto Dream
Auto Dream’s workflow is divided into four stages:
Stage One: Scan
The system scans the agent’s entire memory repository, identifying memory fragments that can be consolidated. Scanning criteria include:
- Temporal dimension: Older memories are more likely to be included in the consolidation scope
- Access frequency: Memories not accessed for a long time are prioritized
- Information density: Memory groups containing significant redundancy or repetition are prioritized
- Relatedness: When multiple memories involve the same topic, they’re flagged as consolidation candidates
Stage Two: Associate
Building on the scan, the system analyzes relationships between flagged memories. The goal of this step is to identify which memories can be merged into a higher-level knowledge unit.
For example, the system might discover that the following 20 independent memory fragments are actually all describing the same thing — the user’s writing style preferences:
- “Feb 3: User shortened agent-generated long paragraphs to short sentences”
- “Feb 5: User requested bullet points instead of continuous paragraphs”
- “Feb 8: User deleted all adjective modifiers”
- “Feb 12: User said ‘be more concise’ in feedback”
- “Feb 15: User kept technical terms but deleted plain-language explanations”
- … (more similar memories)
Although each memory recorded a different event, they collectively point to a unified understanding: the user prefers a concise, direct, technical writing style.
Stage Three: Distill
After establishing relationships, the system distills related memory fragments into more refined knowledge representations.
Continuing the example above, 20 fragmented memories would be distilled into a comprehensive “User Writing Style Profile”:
User Writing Style Preferences:
- Sentence structure: Prefers short sentences, avoids long paragraphs
- Format: Prefers list/bullet point format, avoids continuous narrative
- Vocabulary: Prefers technical terms, doesn’t need plain-language explanations
- Rhetoric: Prefers direct statements, avoids excessive modifiers and adjectives
- Detail level: Prefers high information density, avoids redundant elaboration
- Style confidence: High (confirmed by multiple consistent feedback instances)
This distilled profile is not only more concise than the 20 original memories but also of higher information quality — it extracts commonalities, eliminates noise, and forms structured knowledge that can be directly applied.
Stage Four: Reorganize
After distillation, the system reorganizes consolidated knowledge back into the memory system. Original fragment memories aren’t immediately deleted — they’re marked as “consolidated” and enter an archived state. This means:
- In daily use, the agent prioritizes referencing consolidated knowledge, improving retrieval efficiency
- If you need to trace a piece of knowledge’s origin or details, the original fragment memories remain accessible
- Archived memories are gradually cleaned up over longer time periods, freeing storage space
Memory Lifecycle
Auto Dream is the core component of memory lifecycle management. In DesireCore’s memory system, each memory goes through the following lifecycle stages:
- Active: Newly created memories, frequently accessed and referenced
- Recent: Activity decreases but still maintained in working memory
- Archived: No longer frequently used but retained as historical reference
- Dream (Consolidation): Processed by Auto Dream, consolidated with related memories into refined knowledge
- Compressed: Consolidated knowledge further compressed, retaining only core points
- Purged: Information with no remaining reference value is finally cleaned up
Key principle: Throughout the entire lifecycle, valuable information is never “forgotten” — it simply exists in a more refined form.
This is what “lossless forgetting” means — it appears to be “forgetting” massive amounts of detailed information, but the essence and value of that information are fully preserved. Just as you don’t need to remember the details of every fall while learning to ride a bicycle, but you always remember how to ride.
User Control over Auto Dream
Although Auto Dream runs automatically, DesireCore gives users full control:
- View Dream logs: You can view every consolidation record from Auto Dream, understanding which memories were consolidated and what the results look like
- Manually trigger Dream: If you feel the memory repository has become bloated, you can manually trigger a Dream process
- Pin memories: If a particular memory is especially important to you, you can mark it as “pinned” — pinned memories won’t be processed by Auto Dream and will forever maintain their original state
- Restore original memories: If you’re unsatisfied with a consolidation result, you can undo the consolidation and restore the original fragment memories
- Adjust Dream strategy: You can configure Auto Dream’s aggressiveness — whether it should lean toward preserving details or lean toward refined consolidation
These control mechanisms ensure users always remain the ultimate decision-makers in memory management, rather than passively accepting AI’s automatic processing results.
Auto Dream’s Relationship with Evolution Mechanisms
Auto Dream isn’t merely a storage optimization tool. Deep synergy exists between it and the evolution mechanisms:
- Providing high-quality input for implicit learning: Consolidated memories are more structured than fragment memories, allowing implicit learning algorithms to extract patterns more efficiently
- Validating explicit teaching effectiveness: By analyzing memory changes before and after consolidation, the system can evaluate whether explicit teaching rules are actually being effectively executed
- Enriching review dimensions: The Dream consolidation process itself is a form of “macro review” — not a retrospective of a single task, but a comprehensive examination of all related experiences over a period
- Promoting collaborative evolution: Consolidated knowledge is easier to share among team members — a refined “best practice” document is easier to understand and adopt than a pile of scattered experience fragments
Part Six: The Safety Boundaries of Evolution — What Can Change and What Cannot
A self-evolving AI system sounds both exciting and concerning. Exciting because it truly does become more useful over time, concerning because — if AI can change its own behavior, who ensures it doesn’t become something we don’t want?
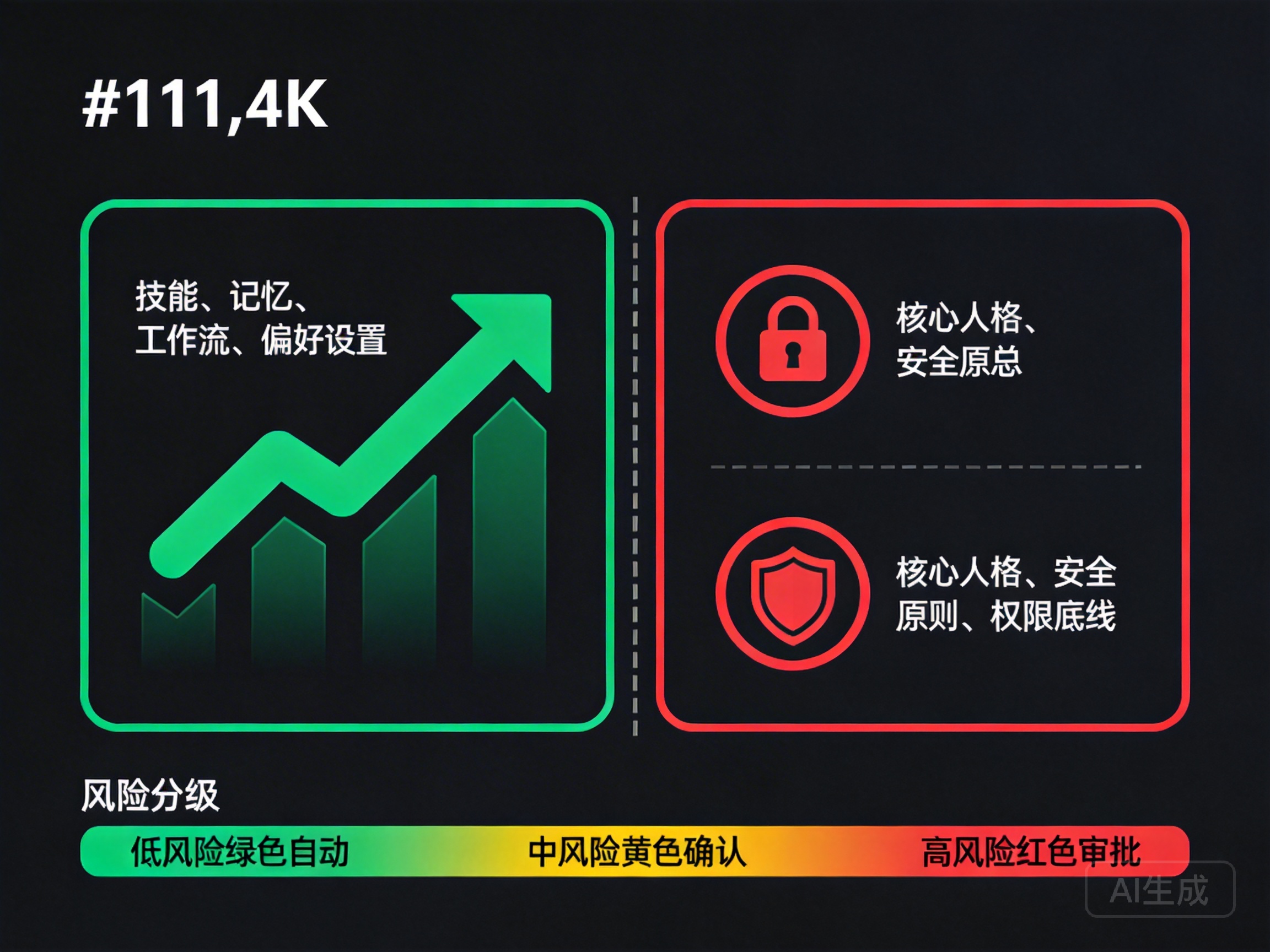
This is a question that demands serious consideration, and one DesireCore invested significant effort into when designing its evolution mechanisms.
The Immutable “Constitution”
DesireCore defines a set of “immutable” core elements for each agent. No matter how the agent evolves, these elements will not be changed. Think of them as the agent’s “constitution” — no “law” (rule) modification can violate the “constitution.”
Immutable content includes:
1. Core Personality Traits
The agent’s fundamental character traits — its attitude, values, and behavioral principles. For example, an agent configured as “cautious and professional” will never evolve into a “casual and aggressive” one, no matter how much evolution occurs.
Users can define core personality traits when creating the agent, and once established, they cannot be modified through normal evolution processes. If core personality changes are truly needed, they require a specialized management process and administrator-level authorization.
2. Safety Principles
These are the most fundamental immutable items. Safety principles ensure the agent never performs dangerous or harmful actions. No matter how users teach it, no matter what experiences the agent accumulates, safety principles always have the highest priority.
Specifically, safety principles include but are not limited to:
- Not generating harmful content
- Not assisting illegal activities
- Protecting user privacy
- Expressing uncertainty when unsure
- Proactively alerting users when potential risks are detected
3. Permission Configuration
The agent’s permission scope — which data it can access, which operations it can perform, which external systems it can interact with — is set by administrators and cannot be expanded through self-evolution.
The agent cannot “unlock” new permissions through learning or experience accumulation. If it needs more permissions to complete a task, it can only suggest to the user, letting the user or administrator decide whether to authorize.
Risk-Tiered Control
Beyond the absolutely immutable “constitution,” DesireCore also implements risk-tiered control for mutable content. Different risk levels have different handling procedures:
Low-Risk Changes: Automatically Applied
Low-risk changes don’t significantly affect the agent’s core behavior and are mainly fine-tuning and optimization. Examples:
- Fine-tuning default response length
- Subtle adjustments to communication tone
- Optimizing task processing order
- Learning format preferences
These changes are automatically handled by implicit learning without user confirmation. Even if an adjustment goes slightly off course, its impact is limited and can be quickly corrected through subsequent feedback.
Medium-Risk Changes: Confirmation Required
Medium-risk changes may noticeably affect how the agent behaves on specific tasks. Examples:
- Adding a new task processing rule
- Modifying the default behavior pattern for a certain domain
- Adjusting quality standards for a certain type of task
- Installing new skill packs
These changes require explicit user confirmation. The system presents changes in a modification proposal (diff) format, and they only take effect after the user reviews and approves them.
High-Risk Changes: Explicit Consent Required
High-risk changes may significantly impact the agent’s overall behavior. Examples:
- Connecting new external tools (MCP)
- Substantially modifying core behavior logic
- Changing rules for handling sensitive data
- Modifying shared knowledge affecting multiple users
These changes require explicit user consent — not just clicking a “confirm” button, but requiring the user to clearly understand the change’s impact and express agreement. The system provides detailed impact analysis to help users make informed decisions.
Reviewability and Reversibility of Changes
DesireCore’s safety governance isn’t just about setting barriers before changes. Equally important is the reviewability and reversibility of changes after they occur:
Reviewability:
All changes — whether automatically applied low-risk changes or confirmed high-risk changes — are completely recorded. You can view the agent’s “change history” at any time, understanding when, why, and what changes were made.
This change history records not just the changes themselves but also the context — What triggered this change? How does behavior differ before and after? If the user confirmed the change, what was the confirmation record?
Reversibility:
Nearly all changes are reversible. If you discover a change led to undesirable results, you can:
- Roll back specific changes: Undo one or more specific changes
- Roll back to a specific point in time: Restore the agent’s state to a historical point
- Selective retention: Choose which changes to keep and which to undo within a set of changes
Rollback operations don’t affect the agent’s core functionality or safety — they only restore the state of behavioral rules and experiential knowledge.
The Philosophy of Safe Evolution
DesireCore’s design philosophy for safe evolution can be summarized in three principles:
- Transparency: Users always know how the agent is changing and why
- Controllability: Significant changes require informed user consent; users can intervene at any time
- Reversibility: Any change can be reviewed and undone; there’s no such thing as “irreversible erroneous evolution”
These three principles together ensure one key objective: The agent’s evolution always serves the user’s interests and never deviates from the user’s intentions.
Part Seven: Practical Scenario — A Complete Case of an Agent from Beginner to Expert
With the theory covered, let’s walk through a complete case study to see how these mechanisms work together in practice.
Background
Zhang is a product manager at a tech startup. He just started using DesireCore and created an agent named “Product Assistant” to help with his daily work.
Day 1: First Meeting
Zhang’s first request is simple: “Help me organize today’s meeting notes.”
He pastes the meeting transcript to the agent. The agent generates a document following a standard meeting minutes format — attendees, time, agenda items, discussion points, and action items. The format is clean and the content is complete, but the output is entirely “template-like.”
Zhang reviews it and thinks it’s okay, but has several issues: action items don’t have assigned owners, the discussion content is too verbose, and it’s missing “Next Meeting Preview” — a standard section in their company.
He edits the document and sends the corrected version back to the agent: “Use this version’s format from now on.”
What happened?
- Explicit teaching activated: The agent generated a rule modification proposal including the new meeting minutes template (with assigned owners, concise discussion content, and added Next Meeting Preview section). Zhang confirmed, and the rule took effect.
- Implicit learning activated: The agent noticed Zhang prefers a concise content style (he found the discussion content “too verbose”) and began fine-tuning text generation detail levels.
- Core memory updated: Recorded Zhang’s occupation (product manager) and company type (tech startup).
Day 7: Beginning to Adapt
A week has passed. Zhang uses the agent daily for various tasks — writing emails, organizing requirements, analyzing competitors, and preparing presentations.
By day 7, some changes are already apparent:
- Meeting minutes formatting is already quite accurate, requiring almost no modifications
- The agent noticed Zhang likes to get straight to the point in emails without preamble or pleasantries, and automatically adjusted the email opening style
- When analyzing competitors, the agent learned Zhang’s priority dimensions — feature comparison, pricing strategy, and user reviews, rather than lengthy company background introductions
That day, Zhang asks the agent to help organize a Product Requirements Document (PRD). The agent produces a standard-format PRD, but Zhang finds it needs significant rework.
So he spends 20 minutes explaining in detail their company’s PRD format: user stories must use a specific template, priorities must use P0-P3 classification, technical solutions only need bullet points without detailed designs, and acceptance criteria must be quantifiable and testable.
What happened?
- Explicit teaching: A set of detailed rules about PRD formatting was established
- Review evolution: The agent reviewed this PRD task and identified that its product documentation knowledge needed strengthening
- Capability expansion suggestion: The agent suggested Zhang install a “Product Management Skill Pack” to enhance PRD, user story, and roadmap handling
- Relational memory updated: Recorded that Zhang has high standards and specific format requirements for PRD tasks
Day 21: Entering Collaboration
Three weeks in, Zhang clearly feels the agent’s growth.
Today, with just one sentence — “Help me prepare materials for tomorrow’s product review” — the agent accurately produces everything he needs:
- Extracted completed and in-progress features from last week’s requirements list
- Organized progress updates in his preferred format
- Flagged risk points that may need discussion
- Prepared a concise presentation outline
What’s even more surprising is the agent proactively reminds him: “In the last product review, the CTO raised questions about performance metrics. Want to prepare performance testing data in advance this time?”
This happened because relational memory stored experience from the last product review, and the agent extracted valuable information and proactively applied it.
On the same day, Zhang’s colleague Li also started using the same “Product Assistant.” Li is a market-facing product manager with different needs than Zhang.
Collaborative evolution begins taking effect:
- The agent established independent core memory and relational memory for Li, remembering that Li focuses more on market data and user feedback
- Meanwhile, both colleagues’ shared company standards (like PRD format and meeting minutes templates) were elevated to shared memory
- When Li used a better competitive analysis framework, the agent proposed adding it to team shared knowledge
Day 45: Auto Dream’s First Run
Six weeks have passed, and the agent has accumulated a substantial amount of memory data. The system automatically triggers the first Auto Dream.
Dream Process:
The scan stage found numerous consolidatable memories. One typical consolidation case:
Zhang had dozens of email-related interactions with the agent over the past six weeks. Memory fragments from these interactions included:
- “Mar 1: Zhang deleted ‘Hello’ from email opening and went straight to content”
- “Mar 3: Zhang condensed three paragraphs of body text to one”
- “Mar 5: Zhang added explicit action items at the end of emails”
- “Mar 8: Zhang changed vague descriptions to specific data”
- “Mar 12: Zhang kept polite language for external emails”
- “Mar 15: Zhang used very direct tone for internal team emails”
- …
Auto Dream consolidated these fragments into a structured “Zhang Email Style Profile”:
Email Style Preferences:
- Internal emails: Start directly, no pleasantries; single-paragraph body; end with action items
- External emails: Maintain basic polite language; body should be concise but complete; action items and timelines must be explicit
- General rules: Prefer data over descriptive language; avoid vague statements; single email should not exceed 200 words (internal) or 300 words (external)
Zhang reviewed the Dream log and was very satisfied with the consolidation results. He also pinned a special communication note about a key client — that memory was too important, and he didn’t want it consolidated or simplified.
Day 90: Mastery Stage
Three months later, “Product Assistant” has become an indispensable part of Zhang’s workflow.
Some typical collaboration scenarios:
Scenario One: Weekly Product Report Zhang only needs to say “weekly report,” and the agent automatically extracts key information from all interactions during the week and generates a complete weekly report following the team template. Zhang usually only needs about 2 minutes to review it before sending.
Scenario Two: New Feature Evaluation When Zhang gives the agent a new feature proposal, it not only analyzes the feature’s feasibility but also automatically cross-references the company’s product roadmap, historical performance data of similar features, and target user group feedback preferences — this knowledge comes from product knowledge in core memory, company data in shared memory, and accumulated analytical experience in relational memory.
Scenario Three: Cross-Team Collaboration When collaborating with design and engineering teams, the agent automatically adjusts content depth and style based on the audience — content for designers emphasizes user experience and visual direction, while content for engineers focuses on technical details and implementation constraints. This capability comes from communication preferences of different roles learned through collaborative evolution.
Scenario Four: Risk Alert Once, while Zhang was preparing a feature proposal, the agent proactively flagged a potential privacy compliance risk — because a similar issue had been discussed in a project review three months earlier. Without the memory system, this risk would likely have been missed, as it occurred dozens of conversations ago.
Case Summary
From day 1 to day 90, this agent went through a complete evolution cycle:
| Milestone | Key Evolution | Primary Driving Mechanism |
|---|---|---|
| Day 1 | Learned meeting minutes format | Explicit teaching |
| Day 7 | Adapted to communication style and content preferences | Implicit learning + review |
| Day 7 | Mastered PRD format | Explicit teaching + capability expansion |
| Day 21 | Proactively provided contextual suggestions | Relational memory + review evolution |
| Day 21 | Team knowledge sharing | Collaborative evolution |
| Day 45 | Memory consolidation optimization | Auto Dream |
| Day 90 | Full mastery, deep collaboration | All mechanisms working in concert |
Conclusion: Making AI a Partner That Truly Understands You Better Over Time
Returning to the question posed at the beginning: Why do traditional AI assistants never “grow up”?
The answer is they lack three things: memory, reflection, and the ability to grow.
DesireCore fundamentally solves this problem through its self-evolution mechanism and memory system:
- Three-layer evolution mechanism (rule learning, experience accumulation, capability expansion) gives the agent multi-level learning capabilities
- Four evolution modes (implicit, explicit, review, collaborative) cover all learning scenarios from individual to team
- Three-domain memory architecture (core memory, relational memory, shared memory) provides structured knowledge storage
- Auto Dream ensures long-term health and efficient operation of the memory system
- Safety governance framework guarantees evolution always stays within safe, controllable boundaries
But technology is just the means — what we truly aim to achieve is an entirely new human-AI collaboration experience. Your AI assistant is no longer a cold tool but a digital companion that genuinely understands you, adapts to you, and grows with you.
It remembers every important preference you’ve mentioned, learns from every task, provides just-right suggestions when you need them, and gently reminds you when you make mistakes. It doesn’t lose its memory from going offline, doesn’t become sluggish from too much data, and doesn’t go out of control from free learning.
This is the vision for DesireCore agents: Smarter with every use, understanding you better each day.
If you’re curious about these capabilities, the best way is to experience them firsthand. Create your first DesireCore agent, give it a task, and observe how it grows over the following weeks. We believe it will redefine your expectations of an “AI assistant.”
This article is based on DesireCore product documentation and technical white papers. The features and mechanisms described reflect DesireCore’s design philosophy and technical architecture. For more technical details or the latest feature updates, please visit the DesireCore website.
